

Target Leakage
What is Target Leakage?
Note: Before reading this entry, familiarize yourself with those on targets; data collection; and training, validation, and holdout.
Target leakage, sometimes called data leakage, is one of the most difficult problems when developing a machine learning model. It happens when you train your algorithm on a dataset that includes information that would not be available at the time of prediction when you apply that model to data you collect in the future. Since it already knows the actual outcomes, the model’s results will be unrealistically accurate for the training data, like bringing an answer sheet into an exam.
“Any other feature whose value would not actually be available in practice at the time you’d want to use the model to make a prediction is a feature that can introduce leakage to your model.” – Data Skeptic
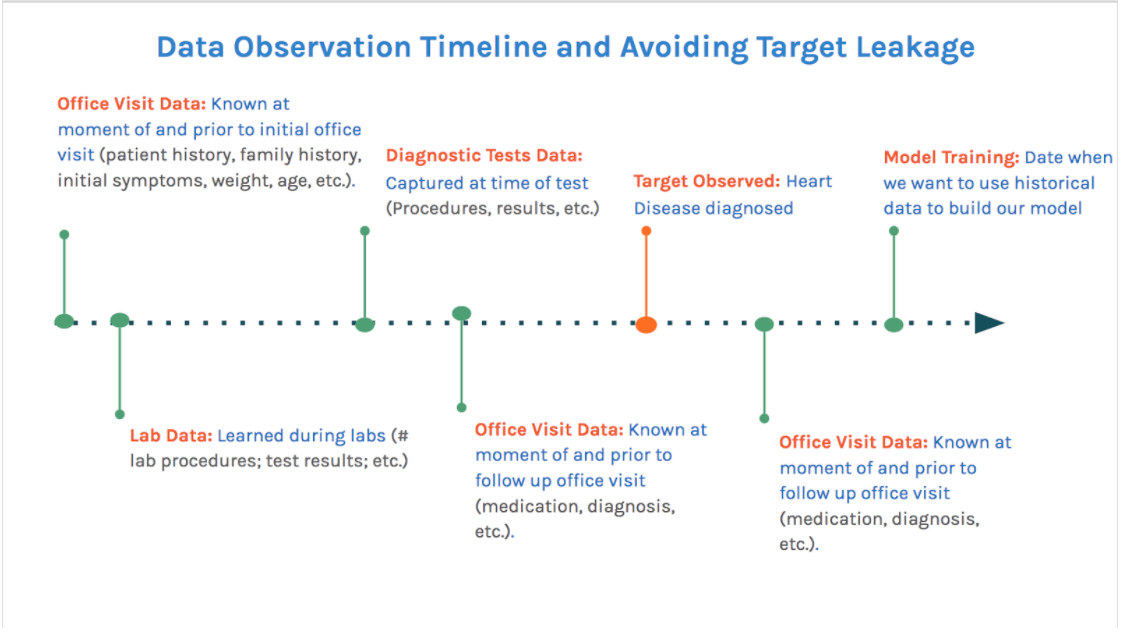
To avoid target leakage, omit data that will not be known at the time of the target outcome. The following timeline shows the process of avoiding target leakage when predicting the outcome of a medical visit, such as whether or not a patient will be diagnosed with heart disease (marked as “target observed”). When constructing your training dataset, you should include data that occurs on the timeline before the “target observed” point, such as office visit data, lab procedure data, and diagnostic test data. However, you should not include data from tests or office visits that occurred after the initial diagnosis of heart disease. Those data will have been collected with the diagnosis in mind, which you won’t know when you apply the model to future data to make a prediction.
Why is Target Leakage Important?
Target leakage is a consistent and pervasive problem in machine learning and data science. It causes a model to overrepresent its generalization error, which makes it useless for any real-world application.
The prevalence of target leakage proves that deep domain knowledge is essential for machine learning and artificial intelligence (AI) initiatives. Business analytics professionals and others with knowledge of the practical application of the machine learning models must be involved in all aspects of data science projects, from problem specification to data collection to deployment, in order to develop models that deliver actual value to the business.
Target leakage is particularly nefarious because it can be both intentional and unintentional, making it difficult to identify. For example, Kaggle contestants have intentionally included sampling errors that resulted in target leakage in order to develop highly accurate models and gain a competitive edge in data science competitions.
Target Leakage + DataRobot
In order to identify and rectify target leakage, you need substantial domain expertise and understanding of the business context in which you’re going to apply your predictive model. Since there is no way to identify target leakage with 100% accuracy, you need to have a deep understanding of your data, critically analyze the model’s outputs, and investigate further if something raises your suspicions.
DataRobot has several features that help you identify possible target leakage:
- Accuracy leaderboard. A perfect or near-perfect accuracy score for a model is a red flag and warrants further investigation.
- Feature impact. DataRobot automatically calculates the impact each variable has on the outcome of each model, and those with a high probability of including target leakage will have an alarmingly high score.