Stacked Predictions
What does Stacked Prediction Mean?
There are some situations in which you want to implement machine learning algorithms on a training dataset rather than a production dataset, such as when you want to prevent overfitting in a multistage modeling process. Stacked predictions, a method by which you build multiple models on different “folds” or sections of the training data, allow you to make “out-of-sample” predictions and prevent misleadingly high accuracy scores.
Before delving into the technicalities of stacked predictions, it is important to understand hyperparameters and cross-validation.
Hyperparameters are configuration parameters that describe the architecture and training process of the model. This is not to be confused with model parameters that describe the model as a result of training. Some examples of hyperparameters are the depth of trees in a Random Forest algorithm or the C and gamma parameters in a Support Vector Machine Classifier.
During the cross-validation process, a model is selected for scoring. Then, the data is further partitioned into five smaller folds upon which DataRobot automatically performs hyperparameter tuning. This process is known as nested cross-validation and is shown in the diagram below.
A stacked prediction is then calculated by appending out-of-sample predictions to all five folds.
Why are Stacked Predictions Important?
Using the training dataset to make in-sample predictions is a bad idea since the model has already “seen” the data, like a student preparing for an exam by practicing on sample exams. If the teacher decides to use the sample questions again on the real exam, the student will almost definitely achieve a high score, but they haven’t learned how to solve new questions.
Stacked predictions ensure that the data used to train the model is different than the data on which you want to ultimately make a prediction, like making sure you don’t repeat any old questions on new exams.
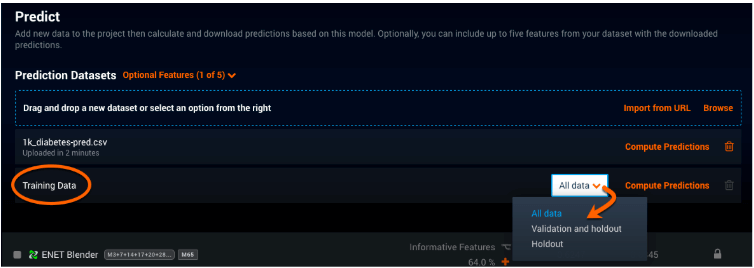
DataRobot + Stacked Predictions
In the DataRobot AI Platform, you can develop models on your training dataset under the “Predict” tab, as shown below. The platform will only employ stacked predictions on small datasets (those less than 750MB). Because it would be too “expensive” to run stacked predictions against all data in a large dataset, DataRobot runs models on validation and holdout data when a dataset exceeds 750MB.