

Data Preparation
What is Data Preparation for Machine Learning?
Data preparation (also referred to as “data preprocessing”) is the process of transforming raw data so that data scientists and analysts can run it through machine learning algorithms to uncover insights or make predictions.
The data preparation process can be complicated by issues such as:
-
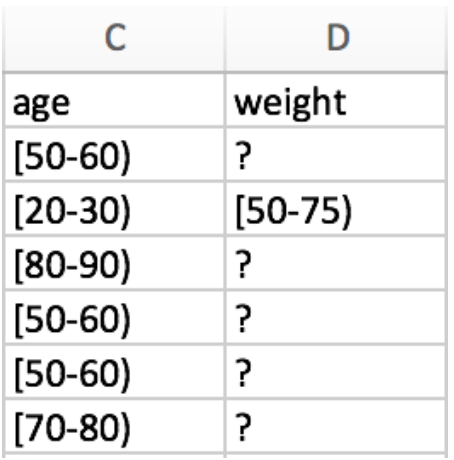
- Missing or incomplete records. It is difficult to get every data point for every record in a dataset. Missing data sometimes appears as empty cells, values (e.g., NULL or N/A), or a particular character, such as a question mark. For example:
- Outliers or anomalies. Unexpected values often surface in a distribution of values, especially when working with data from unknown sources which lack poor data validation controls. For example:

- Improperly formatted / structured data. Data sometimes needs to be extracted into a different format or location. A good way to address this is to consult domain experts or join data from other sources.
- Inconsistent values and non-standardized categorical variables. Often when combining data from multiple sources, we can end up with variations in variables like company names or states. For instance, a state in one system could be “Texas,” while in another it could be “TX.” Finding all variations and correctly standardizing will greatly improve the model accuracy.
- Limited or sparse features / attributes. Feature enrichment, or building out the features in our data often requires us to combine datasets from diverse sources. Joining files from different systems is often hampered when there are no easy or exact columns to match the datasets. This then requires the ability to perform fuzzy matching, which could also be based on combining multiple columns to achieve the match. For instance, combining two datasets on CUSTOMER ID (present in both data datasets) could be easy. Combining a dataset that has separate columns for CUSTOMER FIRST NAME and CUSTOMER LAST NAME with another dataset with a column CUSTOMER FULL NAME, containing “Last name, First name” becomes more tricky.
- The need for techniques such as feature engineering. Even if all of the relevant data is available, the data preparation process may require techniques such as feature engineering to generate additional content that will result in more accurate, relevant models.
- Missing or incomplete records. It is difficult to get every data point for every record in a dataset. Missing data sometimes appears as empty cells, values (e.g., NULL or N/A), or a particular character, such as a question mark. For example:
Why is Data Preparation Important?
Most machine learning algorithms require data to be formatted in a very specific way, so datasets generally require some amount of preparation before they can yield useful insights. Some datasets have values that are missing, invalid, or otherwise difficult for an algorithm to process. If data is missing, the algorithm can’t use it. If data is invalid, the algorithm produces less accurate or even misleading outcomes. Some datasets are relatively clean but need to be shaped (e.g., aggregated or pivoted) and many datasets are just lacking useful business context (e.g., poorly defined ID values), hence the need for feature enrichment. Good data preparation produces clean and well-curated data which leads to more practical, accurate model outcomes.
Data Preparation + DataRobot
The DataRobot AI Platform interfaces with DataRobot Data Prep to assist with the data preparation process.
Data Prep allows data analysts and citizen data scientists to visually and interactively explore, clean, combine, and shape data for training and deploying machine learning models and production data pipelines to accelerate innovation with AI. Data science teams can collaborate, reuse, and share data sources, datasets, and recipes with full enterprise governance and security to ensure compliance with organizational policies.
Once a user has properly prepared a dataset for machine learning, importing it into DataRobot is as easy as exporting the prepared data back to the AI Catalog. If you are not using Data Prep, you can drag and drop a .csv or import it from Hadoop and most popular SQL databases (Microsoft SQL, MS Azure SQL, Postgresql, etc) directly into DataRobot. Users can also directly upload common formats, such as Pandas (Python) or R Data Frames, via DataRobot’s language-specific APIs. No matter your programming skill level, DataRobot has a corresponding import mechanism.

Once a user uploads data to the platform, DataRobot automatically performs exploratory data analysis, identifying each variable type and generating descriptive statistics for numerical records (mean, median, standard deviation, etc.). This allows analysts and data scientists to easily explore data, eliminating the need to manually slice-and-dice it using Excel or other similar software. DataRobot also automatically imputes missing values when necessary and provides graphical tools for manually deriving additional features.