

Automated Feature Engineering
What’s the secret of the world’s top-ranked data scientists? How do they build the most accurate machine learning models? According to Sergey Yurgenson, formerly ranked the #1 global competitive data scientist on Kaggle, the secret is feature engineering.
“Feature engineering is the art part of data science” – Sergey Yurgenson
Feature engineering is the process of preparing a dataset for machine learning by changing features or deriving new features to improve machine learning model performance. For example, suppose a lender wants to predict which loans will go bad. The lender has the borrowers’ incomes and the monthly repayment amount of each loan. While these two values will almost certainly be individually predictive of the probability of default, creating an extra column that calculates the loan repayment amounts as a percentage of the borrowers’ income adds additional insights and will get the lender an even more accurate model.
Feature engineering can include:
-
Finding new data sources — e.g. credit scores from an external agency, or
-
Applying business rules — e.g. flagging banking transactions that exceed authorization limits, or
-
Regrouping or reshaping data — e.g. calculating the body mass index for a hospital patient.
Automated feature engineering’s key strength is when it’s applied to regrouping or reshaping data. This is why we recommend that you engage the creativity and experience of your business domain experts for domain-specific feature knowledge, such as how to correctly interpret the data.
Why Is Feature Engineering So Difficult?
Firstly, you need deep technical skills to do feature engineering. It requires detailed knowledge of how each machine learning algorithm works because different algorithms require different feature engineering methods. A recent benchmarking study demonstrated that successful artificial intelligence (AI) comes from model diversity, i.e. training multiple algorithms on the data. Using a diverse set of algorithms creates the demand for a diverse set of engineered features that correctly pair with those algorithms. This quickly adds up to a lot of time and effort involved with feature engineering.
Feature engineering often requires database, coding, and programming skills. There is a lot of trial and error for testing the impact of newly created features. This can be repetitive, mundane work, and at the end of it all, you may discover that adding more features can actually make the accuracy worse!
Secondly, you usually need domain expertise — an understanding of the business and the data. For example, in medical use cases, it is helpful to know that two differently named pharmaceuticals are the same drug, where one is a proprietary brand name and the other is the generic version. In such a situation, feature engineering could include grouping these two drugs together so that they are treated the same by the algorithm.
A good general principle to apply when considering the use of domain knowledge is to avoid making a machine learning algorithm learn something that you already know. Applying this principle saves processing power that can instead be used for finding new and undiscovered patterns in the data. For example, if you are predicting sales for a retail store, then you should add features that identify key shopping periods e.g. the weeks leading up to Christmas.
Feature engineering is resource-intensive and time-consuming. The technical skills and domain knowledge required for best-practice feature engineering can take years to develop. People with both of these skills are rare. The trial and error application of these skills in a data science project can take years.
How DataRobot Automates Feature Engineering
Luckily, whenever a process is repetitive and time-consuming, it is a strong candidate for automation. DataRobot automates repetitive and time-consuming feature engineering by building an expert system that:
- automatically generates new features,
- knows which algorithms require feature engineering,
- knows what types of feature engineering work best with each algorithm, and
- does systematic head-to-head model comparisons that show which combination of feature engineering and algorithm worked best on your data.
DataRobot does this via model blueprints, which intelligently match feature engineering with compatible machine learning algorithms. Let’s look at one of the simpler model blueprints:

In the simple model blueprint above, DataRobot prepares the data for a regularized logistic regression algorithm. There are two feature engineering steps that are tailored for this algorithm:
- One-hot encoding: Regularized Logistic Regression algorithms do not directly accept categorical data (e.g. gender). DataRobot knows that it should apply one-hot-encoding (creating a new column for each possible value of the categorical feature) as the feature engineering step for the categorical variables for this algorithm.
- Missing value imputation: Regularized Logistic Regression algorithms cannot work with missing numerical values. For example, if you are building a credit risk model with a field containing the number of years since the applicant was last declared bankrupt, this field will rightfully be empty for most applicants. DataRobot knows that it should carry out missing value imputation as a feature engineering step.
- Standardizing: Standardizing numeric features (scaling values to lie within the same range) is particularly important Regularized Logistic Regression algorithms. DataRobot adds this steps because it knows that this is best practice.
Sometimes these simple model blueprints do well, but many times it is the more complex model blueprints that perform best on a dataset. For example, here is a more complex model blueprint for a Gradient Boosted Greedy Trees algorithm:
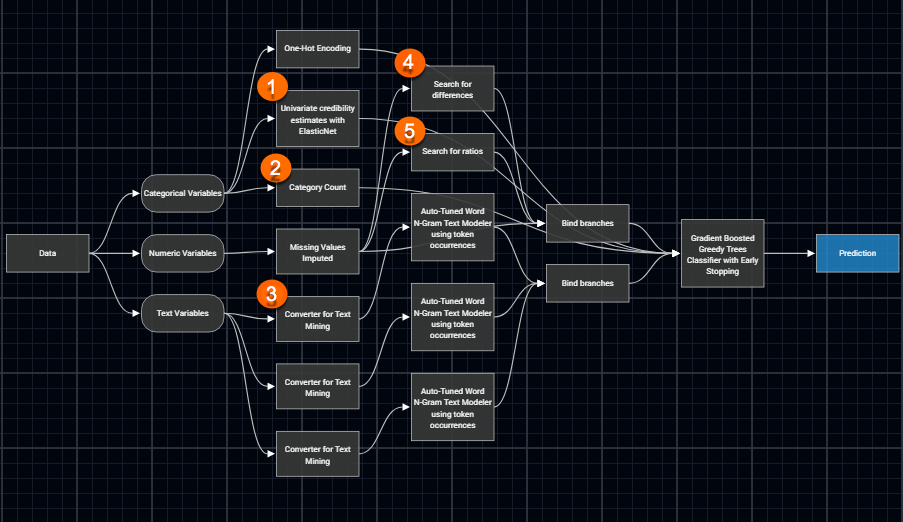
This time there are several feature engineering steps, including the following new steps:
- Univariate credibility estimates: Sometimes you have a rare value in a category and there aren’t enough examples for the algorithm to provide credible estimates. DataRobot knows that the Gradient Boosted Greedy Trees algorithm can perform better if it first applies credibility weighting to rare categorical values.
- Category count: Earlier we saw DataRobot using one-hot encoding on categorical values. Here DataRobot takes a more advanced approach, counting how often a value appears in a categorical column. You can think of this feature engineering as creating a popularity measure for a value.
- Text mining: Gradient Boosted Greedy Trees cannot directly process free-form text. For example, a loan underwriting algorithm will include the applicant’s written description of the purpose of the loan. DataRobot knows this and first applies text mining, feeding the text mining scores into the final algorithm.
- Search for differences: Sometimes it is the difference between two numeric variables that matters more than the individual values. For example, in economic modeling the “real interest rate” (the official government interest rate minus the inflation rate) can be an important predictor. DataRobot knows that a Gradient Boosted Greedy Trees algorithm often performs better when this feature engineering step is included.
- Search for ratios: For some use cases, such as credit scoring, the ratios of columns can be more important than their absolute values. For example, the ratio of debt-to-income can be an important input. DataRobot knows that Gradient Boosted Greedy Trees algorithms often perform better when a ratio feature engineering step is included.
Since its founding in 2012, DataRobot has focused on automated feature engineering that addresses the unique requirements of each and every algorithm incorporated in its vast library of model blueprints. The two examples above are just a small sample of the automated feature engineering built into the DataRobot platform; for each new project, DataRobot chooses a mixture of feature engineering and algorithms, then systematically compares the results from each approach to rank how accurately each algorithm works on your data.
Testing the Added Value From Automated Feature Engineering
Since DataRobot systematically tests a broad range of feature engineering steps and compares their accuracy, it was easy to set up a benchmarking exercise to compare the performance of model blueprints with and without automated feature engineering. I set up DataRobot to work as a model factory, using 27 different datasets from a range of industries such as healthcare, finance, real estate, telecommunications, and energy. In total, DataRobot built hundreds of machine learning models. If I had to do this manually this would have taken several weeks, but with automated machine learning, this only took me a few hours.
I compared the leaderboard rankings of a single algorithm (Gradient Boosted Trees) to give a like-for-like comparison with varying numbers of feature engineering steps. In total DataRobot built 484 Gradient Boosted Trees blueprints.
The plot below compares the top-ranked model blueprints for Gradient Boosted Trees (GBTs), with and without feature engineering, and the top-ranked model blueprints for other algorithms, with and without feature engineering. For a more complete comparison, I also included ensembles.
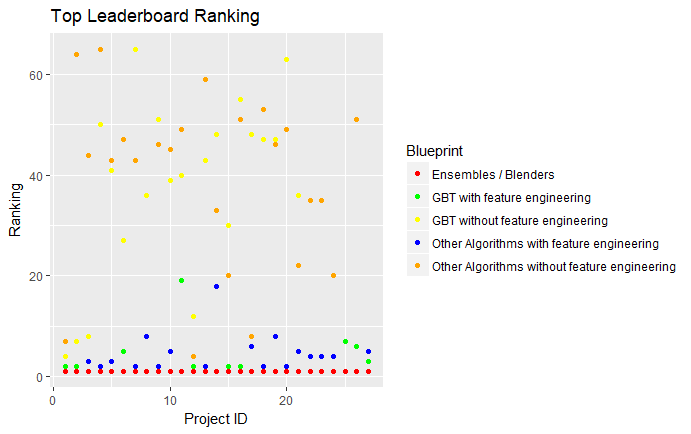
From left to right, you see the results from each project. From top to bottom we see the how well a model performed. The lower a point on the plot, the better a model’s ranking (the best ranking is number 1!).
The yellow and orange points represent the most accurate model blueprints that do not include feature engineering. These points typically have poor leaderboard rankings. The blue and green points represent the most accurate model blueprints using automated feature engineering. These points have much better rankings. Finally, the red points represent the most accurate ensembled/blended model blueprint, and these blueprints, which take advantage of automated feature engineering of each included model in the blender, always gained top ranking.
Across the benchmark projects, the ranking for DataRobot’s automated feature engineering significantly outperformed algorithms without feature engineering. The best results came from ensembling a diverse range of algorithms which incorporate automated feature engineering.
Conclusion
At DataRobot, we believe that the best results for building AI and machine learning applications comes from automating feature engineering that is uniquely optimized for each machine learning algorithm in a diverse library of algorithms. This could comprise some feature engineering that is common across multiple algorithms, as well as feature engineering unique to a particular algorithm. The key to effective automated feature engineering is pairing diverse algorithms with a curated set of paired feature engineering steps in our model blueprints, which delivers outstanding model accuracy in minutes or hours instead of weeks or months.
Everyone’s data is different. What works best for one dataset can be completely different from what works best for another. To see DataRobot in action, ask for a demo, or better yet, arrange for a proof of concept project on your data.

About the Author:
Colin Priest is the Director of Product Marketing for DataRobot, where he advises businesses on how to build business cases and successfully manage data science projects. Colin has held a number of CEO and general management roles, where he has championed data science initiatives in financial services, healthcare, security, oil and gas, government and marketing. Colin is a firm believer in data-based decision making and applying automation to improve customer experience. He is passionate about the science of healthcare and does pro-bono work to support cancer research.

Colin Priest is the VP of AI Strategy for DataRobot, where he advises businesses on how to build business cases and successfully manage data science projects. Colin has held a number of CEO and general management roles, where he has championed data science initiatives in financial services, healthcare, security, oil and gas, government and marketing. Colin is a firm believer in data-based decision making and applying automation to improve customer experience. He is passionate about the science of healthcare and does pro-bono work to support cancer research.
-
DataRobot Recognized by Customers with TrustRadius Top Rated Award for Third Consecutive Year
May 9, 2024· 2 min read -
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read
Latest posts
