機械学習を用いた要因分析 – 実践編
DataRobotのデータサイエンティスト山本祐也です。
今回は2018年7月に開催しましたワークショップ「機械学習を使った要因分析」から、ハンズオンでの実践を中心にご紹介したいと思います。理論面については伊地知さんによる「理論編 Part 1 (8/13公開)」「理論編 Part 2 (8/20公開)」をご参照ください。
今回用いるデータセットは、Stack OverflowのAnnual Developer Surveyです。Stack Overflowは開発者向けの主にプログラミングに関するQ&Aサイトです。今回はその年次アンケートの2017年版を用いてDataRobotによる年収入の予測モデルを構築し、その要因分析を行ってみたいと思います。
なお、元のデータセットは多数の国のデータでしたが、今回はUSのデータのみを抜き出して分析します。順を追ってご説明しますので、DataRobotユーザーの方は是非トライしてみて下さい。
予測モデルの構築
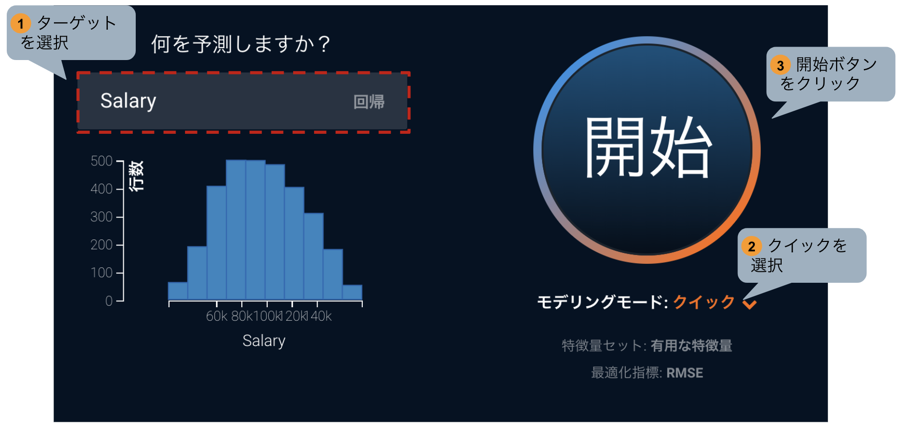
まずはいつも通りにDataRobotを用いて入力データから年収入を予測するモデルを構築します。DataRobotユーザーの方ならご存知のようにこれは非常に簡単で、以下の3ステップで行うことができます。
- データセットをドラッグ&ドロップしてDataRobotにアップロードする。
- 予測ターゲット(今回の場合は”Salary”)を設定する。
- 開始ボタンをクリック。
今回はさらに素早くモデリングを完了するためにモデリングモードを「クイック」に設定しておきましょう。通常の「オートパイロット」ではデータの分布やサイズに応じてDataRobotの推奨する前処理とアルゴリズムの組み合わせが30~40個自動的に実行されますが、「クイック」では10個程度に絞り込まれるため、迅速な検討が可能になります。
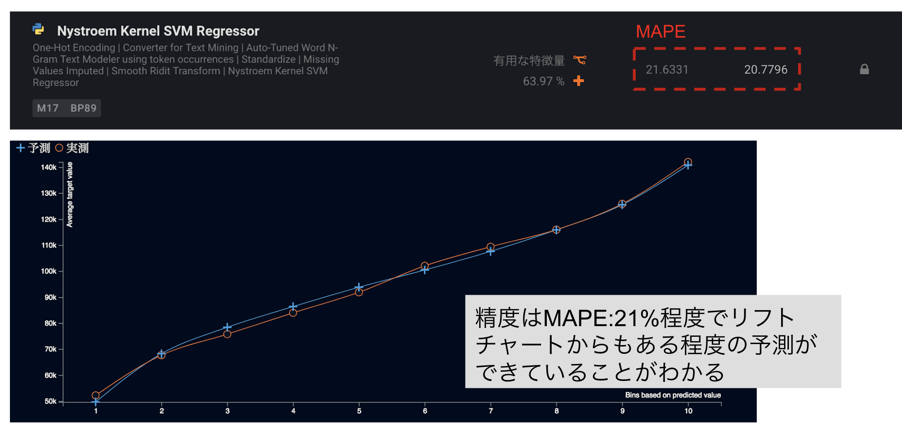
 それではできたモデルを見てましょう。モデルタブからリーダーボードにアクセスすることができます。リーダーボードとは、精度の良い順に作成されたモデルが並んだ順位表で、ここでモデルの精度を確認することができます。モデルをソートする指標もここで選択できますので、解釈性を考えてここではMAPEにします。リーダーボードトップのSVMでMAPEがおよそ21%程度となっており、ある程度意味のある予測ができていることが確認できます。また、リフトチャートからも予測が実測にフィットしており、予測できていることがわかります。これらの結果から、このモデルは要因分析に用いるのに足ると判断し、いよいよ今回の目的である要因分析に移ることにします。
それではできたモデルを見てましょう。モデルタブからリーダーボードにアクセスすることができます。リーダーボードとは、精度の良い順に作成されたモデルが並んだ順位表で、ここでモデルの精度を確認することができます。モデルをソートする指標もここで選択できますので、解釈性を考えてここではMAPEにします。リーダーボードトップのSVMでMAPEがおよそ21%程度となっており、ある程度意味のある予測ができていることが確認できます。また、リフトチャートからも予測が実測にフィットしており、予測できていることがわかります。これらの結果から、このモデルは要因分析に用いるのに足ると判断し、いよいよ今回の目的である要因分析に移ることにします。
モデルから得られるインサイトの確認と因果仮説の立案
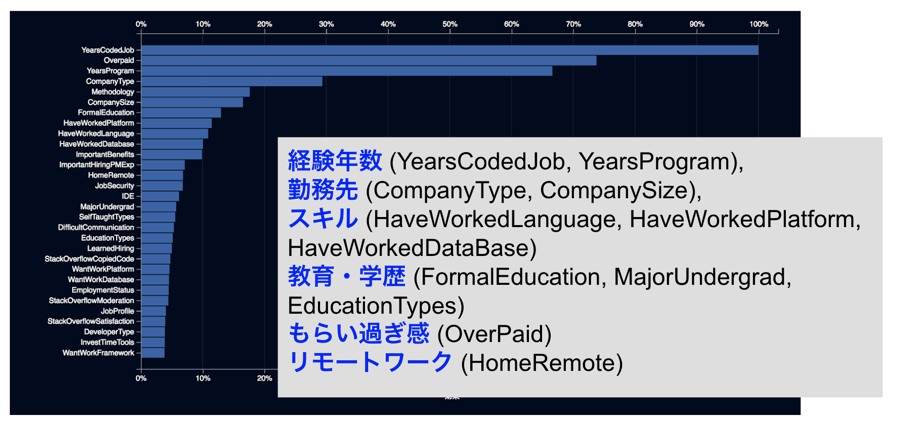
予測モデルの作成が完了したら、モデルからどのようなインサイトが得られるかを確認します。「特徴量のインパクト」から、このモデルが年収入を予測する上でどの特徴量のインパクトが大きいかを知ることができます。今回の例ですと、以下のようにコーディング関連の経験年数、勤務先、学歴・教育、現在の年収入に対するもらい過ぎ感、リモートワークの有無などがインパクトの高い特徴量であることが見てとれます。
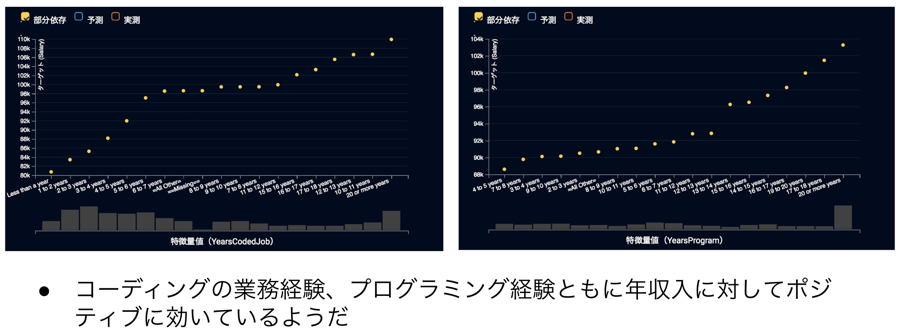
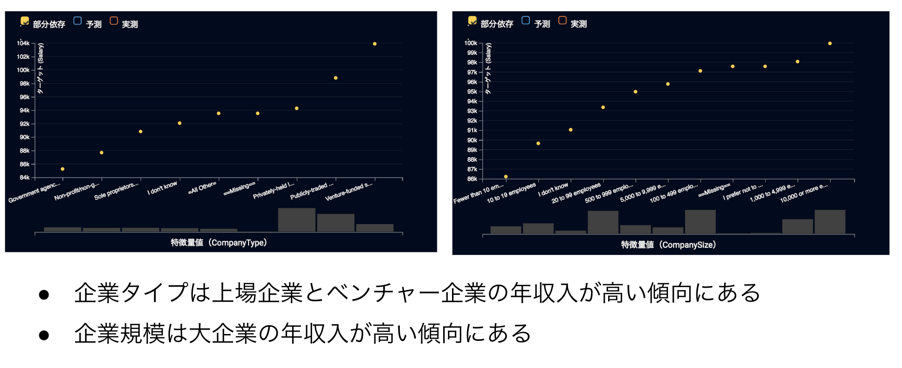
 さて、特徴量のインパクトはどの特徴量が効いているかを非常にわかりやすく示してくれますが、どのように効いているかはわかりません。そこで、「特徴量ごとの作用」が役に立ちます。例えば、コーディング関連の経験と勤務先関連については以下のようなインサイトを得ることができ、経験年数が年収入に対してポジティブに作用していること、上場企業とベンチャーの年収入が高く、企業規模が大きいほど年収入が高い傾向が見て取れます。この辺りは皆様の感覚的にも違和感のないところではないかなと思います。
さて、特徴量のインパクトはどの特徴量が効いているかを非常にわかりやすく示してくれますが、どのように効いているかはわかりません。そこで、「特徴量ごとの作用」が役に立ちます。例えば、コーディング関連の経験と勤務先関連については以下のようなインサイトを得ることができ、経験年数が年収入に対してポジティブに作用していること、上場企業とベンチャーの年収入が高く、企業規模が大きいほど年収入が高い傾向が見て取れます。この辺りは皆様の感覚的にも違和感のないところではないかなと思います。
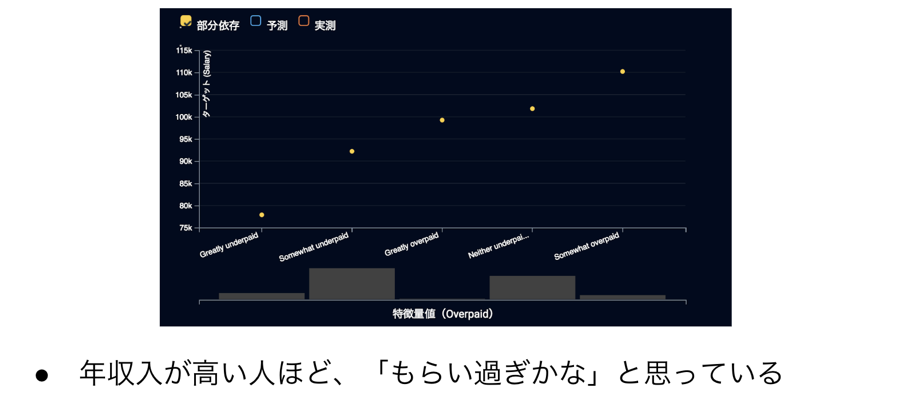
その他では、現在の年収入が高い人ほど、もらい過ぎ感を感じていることがわかります。これも感覚的に違和感はありませんが、おそらくこれは年収入の要因ではなく、むしろ結果であろうと考えられます。
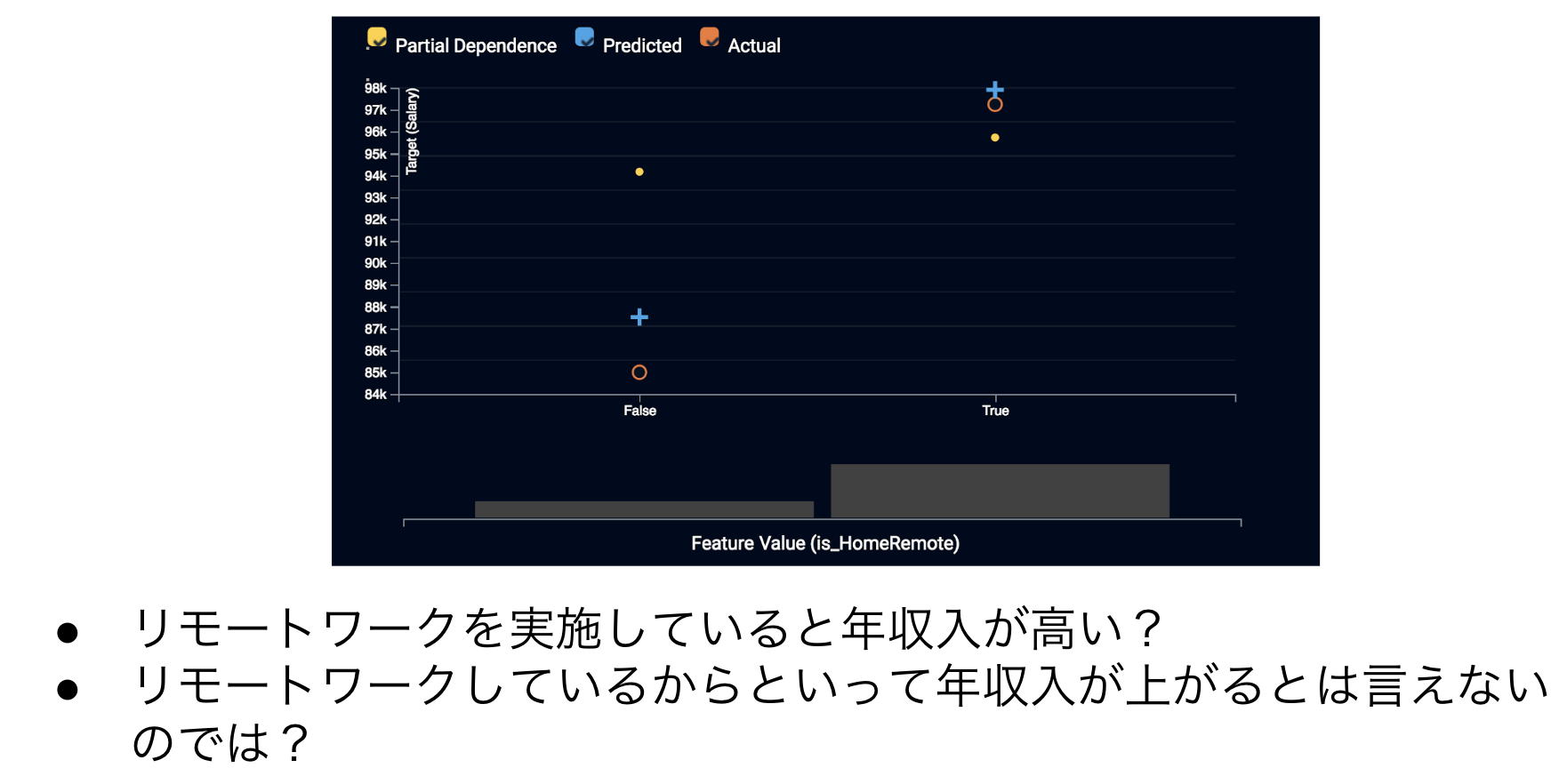
では、リモートワークの有無についてはどうでしょうか?特徴量ごとの作用を見るとリモートワークをしている人の方が年収入が高い傾向があるように見えます。しかし、これは本当でしょうか?経験やスキル、学歴が年収入に寄与するのはイメージできますが、リモートワークについては自明ではない気がします。
さて、ここまでに得られたインサイトをまとめると、以下のようになるかと思います。このように因果関係を原因から結果に矢印を引いた図を因果ダイアグラムと言いますが、ドメイン知識から因果の方向を推定可能なことも多いです。
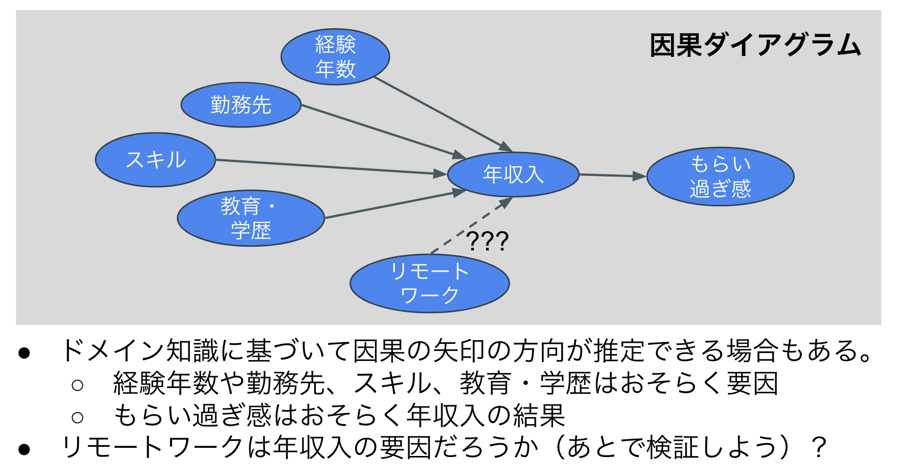
このように、要因分析においてはある因果仮説のもとに、着目している部分について因果か否かの分析を行います。言い換えると、全く仮説がない状態から全ての要素について因果を特定するのは現実的ではないとも言えます。
特徴量選択について
ここで、因果仮説を考える際にはインパクトの高い少数の特徴量 (Vital Few Features, VFFs) に絞り込むことが有用です。DataRobotを用いた上手な特徴量選択の方法をここでご紹介します。
まず、構築したモデルの解釈タブから特徴量のインパクトを表示します。このチャートの上部に特徴量選択のための入力欄があります。ここに特徴量セットを上位何個に絞り込むのかの設定と新しい特徴量セットの名前を入力して作成をクリックすることで簡単に特徴量選択を行うことができます。
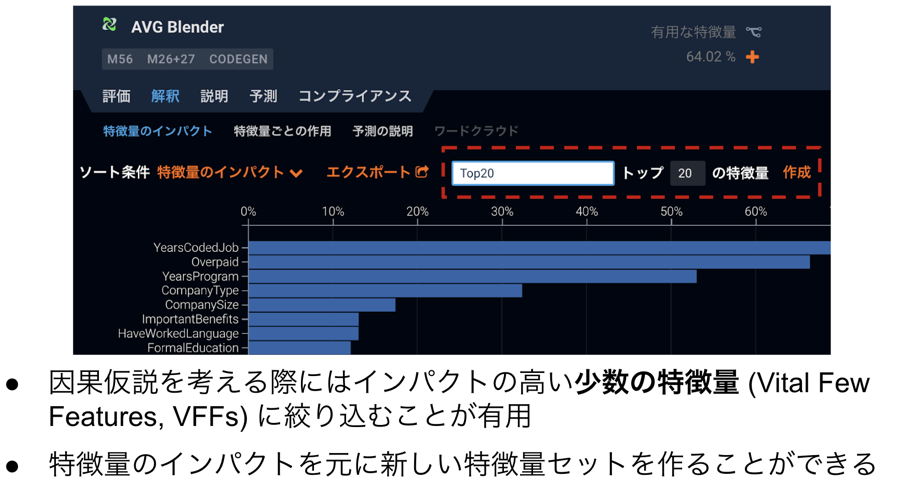
この時、以下の表のように一気に1ステップで所望の特徴量数まで絞り込む方法、少しずつ繰り返し絞り込んでは再度予測モデルの構築と特徴量のインパクトの再計算を繰り返す方法があります。前者は簡単かつ迅速というメリットがあり、後者は時間がかかるものの多重共線性(マルチコ)への対処としてベターであるというメリットがあります。
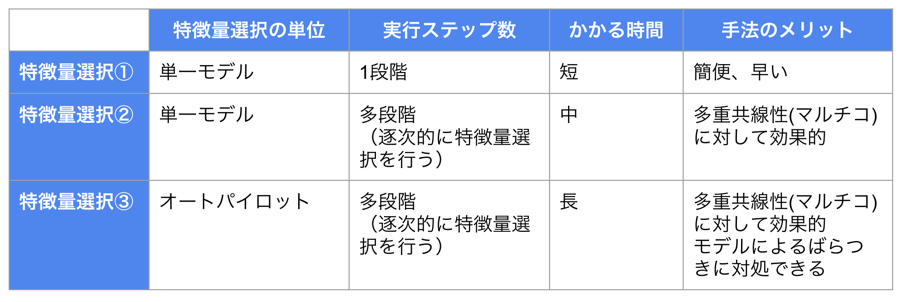
逐次的な特徴量選択が多重共線性に対して定性的に良い結果を与える説明としては、 互いに相関する特徴量のペアは特徴量のインパクトの計算において両方のインパクトが過小評価されており、インパクトの小さい一方を除去することでもう一方の過小評価が解消されてインパクトが向上するためです。手間はかかりますが、この手法は要因分析だけでなく予測精度を向上させる上でも有用ですので是非使って頂きたいと思います。
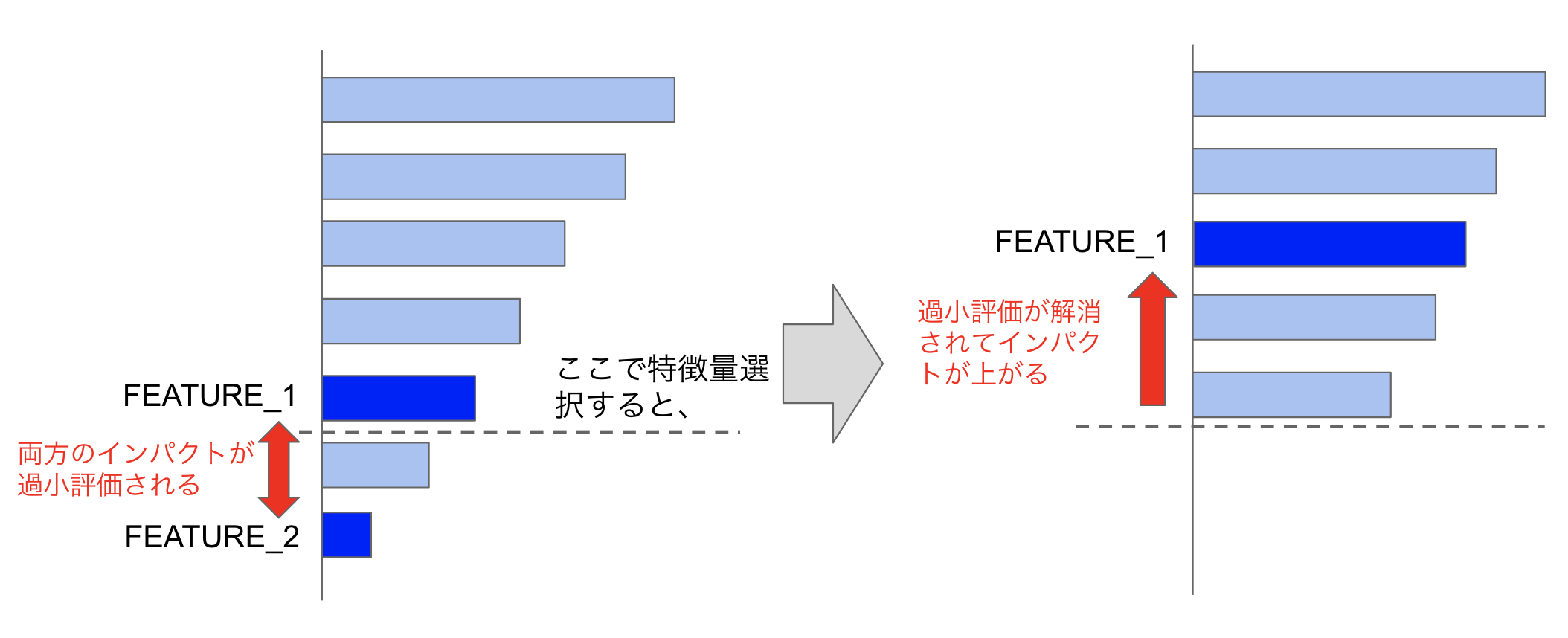
リモートワークは因果だろうか?
いよいよリモートワークが年収入の要因かどうかの分析を行って行きます。そもそも因果とは介入効果によって定義づけられるわけですから、一番良い方法は実際に介入試験を行うことです。そして、その際には一人の人間は二つの人生を同時には歩めないわけですから、個人間の比較を行うのではなく、介入の有無以外は公平となるような集団同士を比較する「ランダム化比較試験 (RCT)」が良い方法の一つとなります。この辺りは「理論編 Part 2」でも説明のあった通りです。
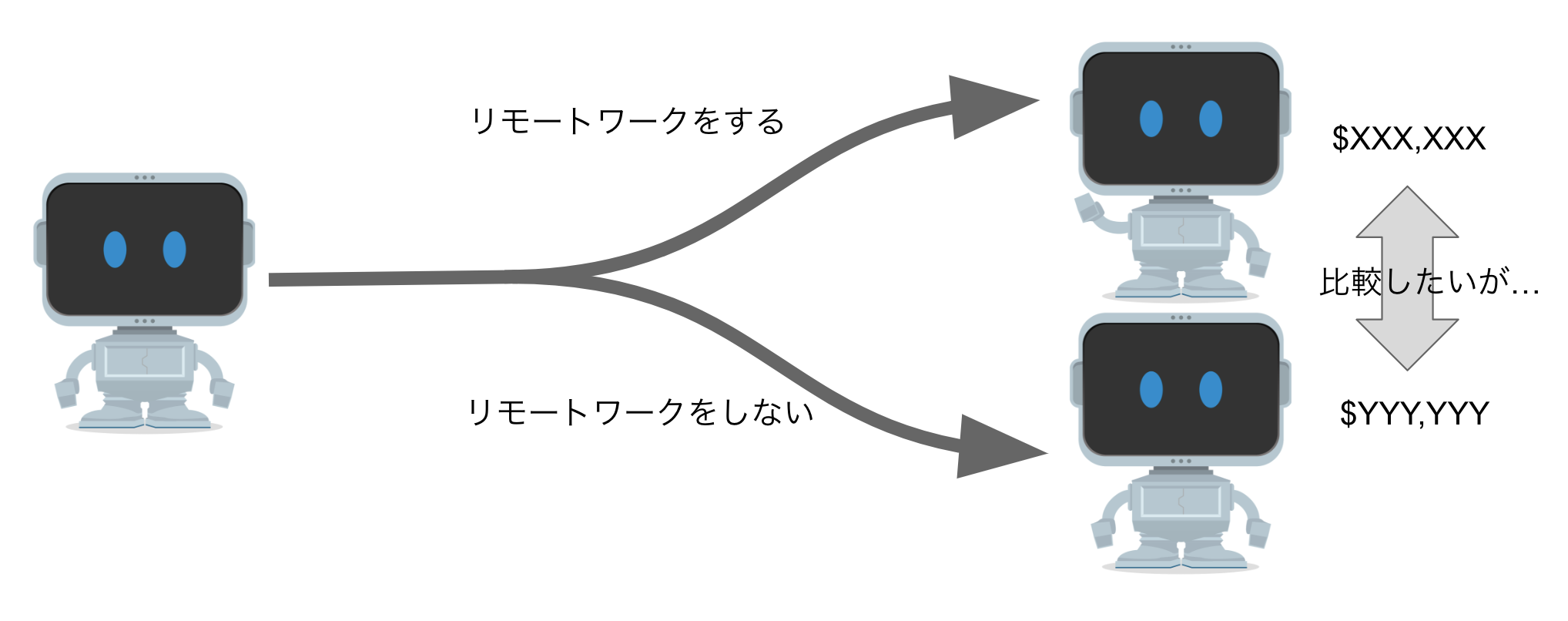
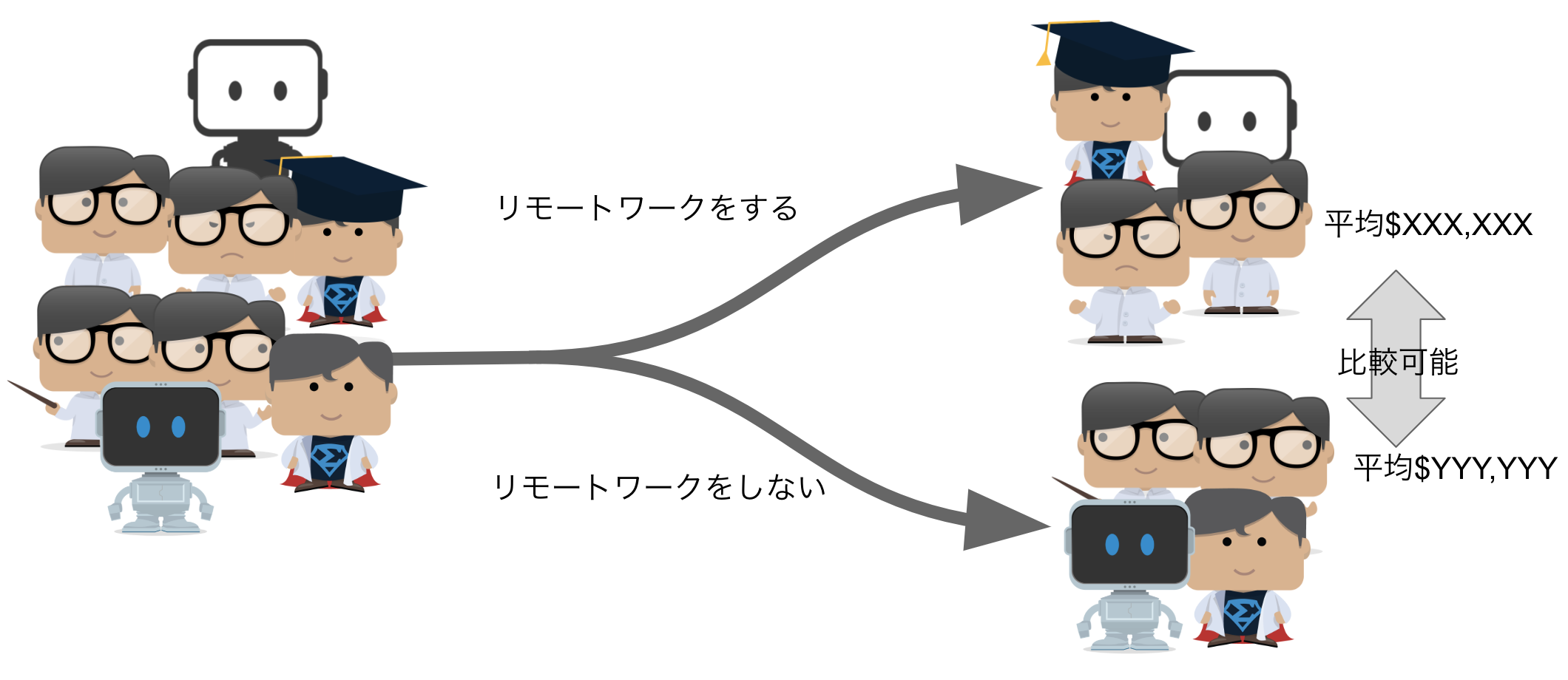
データから介入試験に相当する部分を探して分析する
しかし、介入試験は常に現実的に可能とは限りません。お金も時間も手間もかかりますし、場合によっては医療の場合などで倫理的に許されないケースもあります。そこで既に取られたデータの観察研究から因果関係の推論がよく行われます。その際には、データから介入試験に相当する部分(自然実験)を抽出して分析を行います。では、リモートワークと年収入の因果関係を分析するに当たって、現状の「リモートワーク群」と「非リモートワーク群」は介入試験に相当する部分であると言えるでしょうか?両群を比較してみましょう。
選択バイアスの有無を確認する
両群の比較を行う上で、「リモートワーク群か否かを予測するモデル」を作成します。ターゲットに「is_HomeRemote」を指定し、不要な特徴量を除外した上でモデリングを行い、各機能からのインサイトを確認することで、リモートワークしている群とリモートワークしていない群に、リモートワーク以外にどのような差異があるかを確認することができます。
まず、リーダーボードからAUCスコアをみてみると、0.69と一定程度分離できており、両群は他の区別できてしまう、言い換えると選択バイアスがあるということがわかります。では、何が異なるのでしょうか?特徴量のインパクトをみてみると、「重視している福利厚生」や「経験したプラットフォーム」、「職種」などが異なることがわかります。
さらに詳しく見てみましょう。先ほど名前が上がった特徴量はテキスト型ですが、DataRobotはテキストマイニング機能も有しており、そこから得られたインサイトも例えばワードクラウドとして非常にわかりやすく可視化してくれます。

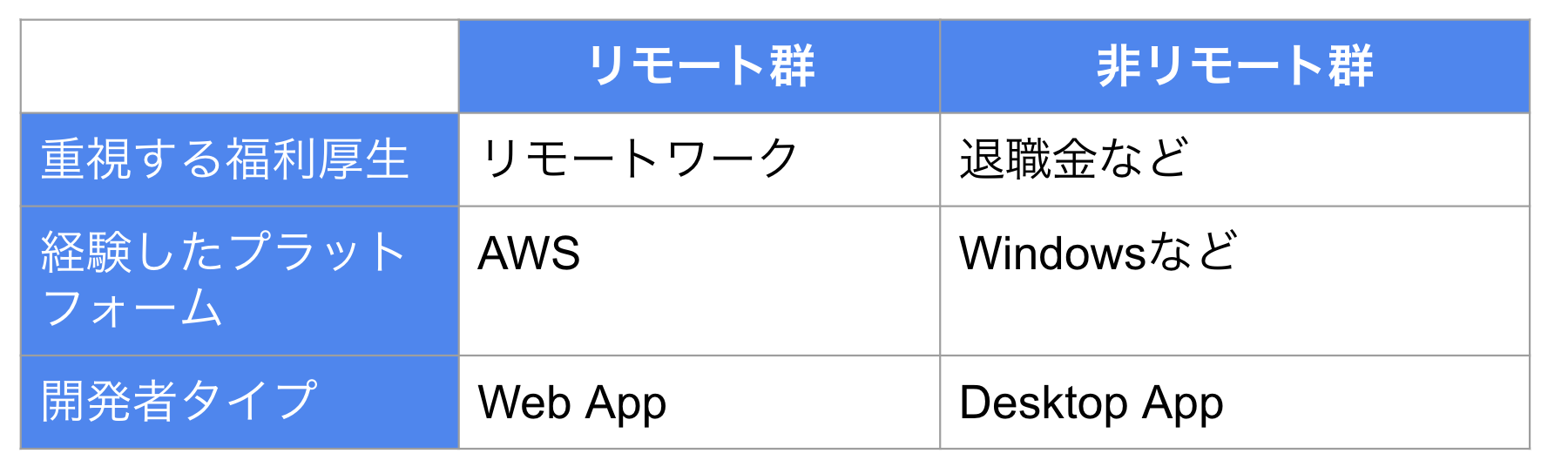
このワードクラウドはリモートワークしている方向に予測上寄与していると赤く、そうでない場合には青く表示されています。また、文字のサイズが大きいほど該当するレコード数が多いことを示しています。どうやら、リモートワークしている人たちはリモートワーク可であることを福利厚生として重視しており、AWSを経験しており、Web Appの開発をしているようです。一方、非リモート群は退職金を重視しており、Windowsを用いていて、Desktop Appを開発している傾向がみて取れます。表にまとめると以下の通りで、両群はリモートワークの有無以外にも大きく異なることがわかりますね。これでは、この両群を比較してもリモートワークと年収入の関係を調べる上でフェアな比較とは言えないことがわかります。では、どうすれば良いのでしょうか?
傾向スコアマッチングによる選択バイアスの補正
「理論編 Part 2」でも言及されていましたが、データから比較可能な部分を抽出する非常に有用な手法として傾向スコアマッチング法というやり方があります。これは、各群に属する予測確率(傾向スコア)の分布が両群で同じになるようにサンプリングを行う手法です。傾向スコアの取得方法はとても簡単で、以下のようにトレーニングデータに対する予測結果を計算・ダウンロードするだけです。複雑なアンサンブルモデルのout-of-fold predictionをクリック一発で取得できるのもDataRobotならではかなと思います。
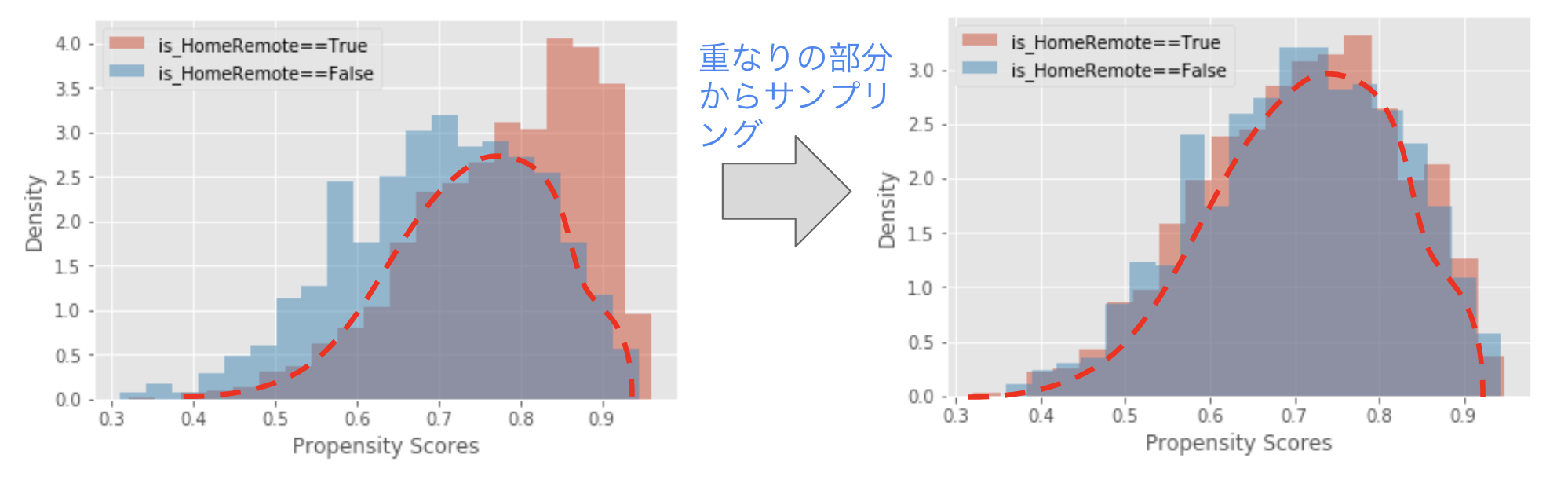
得られた予測値をヒストグラムにしてみましょう。傾向スコアマッチング前の左のヒストグラムでは、赤のリモートワークをしている群と青のしていない群では分布が大きく異なり、選択バイアスがあることがわかります。ここで、ヒストグラムの赤と青の重なりの部分からサンプリングすることで、右のように赤の分布と青の分布がほぼ重なるようにすることができました。このように、傾向スコアマッチングによって両群の傾向スコアの分布を同じにすることで、データセットに含まれる交絡因子の影響をシャットアウトすることができ、選択バイアスを除くことができるのです。
傾向スコアマッチング済のデータを用いて再モデリング
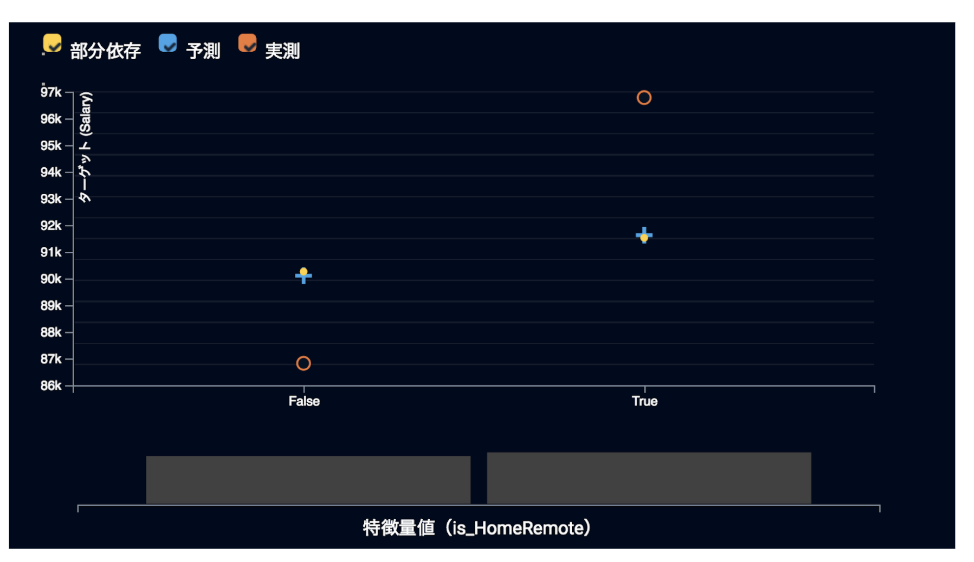
傾向スコアマッチングを行なった後のデータを用いて年収入を予測するモデルをもう一度構築し、リモートワークの影響を調べてみましょう。傾向スコアマッチング後の特徴量ごとの作用でも、右のリモートワークをしている群の方が左のしていない群よりも年収入が高く、要因である可能性があることがわかります。なお、ここで注意が必要なのは、傾向スコアマッチングで除くことができるのはデータセットに含まれる交絡因子の影響のみなので、データセットに含まれない交絡因子が真の要因である可能性は残ります。したがって「理論編 Part 2」にもありましたが、事前に交絡因子を十分に検討することが非常に大事です。
まとめ
以上、DataRobotによる要因分析はいかがでしたでしょうか?DataRobotは予測だけではなく、要因分析や生存分析、入力パラメータ最適化などの様々な領域でお役に立つ製品です。今回用いたデータセットと資料、スクリプトは全てconnpass上から取得可能ですので、是非とも合わせてご活用頂ければと思います。
参考書籍
本ブログ作成にあたっては、下記書籍を参考にしました。要因分析/因果解析についてもっと勉強したいと思っている方に、2018年8月時点で最も推薦できる良書です。
1.データ分析の力 因果関係に迫る思考法 (光文社新書), 伊藤 公一朗 (著)

2.岩波データサイエンス Vol.3, 岩波データサイエンス刊行委員会 (編集)

DataRobot Japanでは、様々なポジションで人材を募集しています。DataRobot で、世界で最も才能のあるデータサイエンティスト、エンジニア、ソートリーダーと共に、ビジネスのしくみを変えてみませんか。私たちはグローバルに、既存の枠にとらわれずに物事を考えることを理念としています。また、同僚を友人として見ています。

DataRobot データサイエンティスト。Kaggle Master、博士 (工学)。東京大学大学院工学系研究科にて有機無機複合材料の研究で博士号を取得。学位取得後、大手化学メーカーにて液晶・タッチパネル関連先端化学材料の研究開発に従事。その後、大手食品メーカーで機械学習を用いた食品パッケージに関する予測モデリングと最適化に取り組むなど、BtB と BtC いずれにも深い経験を有する。余暇では機械学習コンペティションの Kaggle に精力的に取り組んでおり、 2020年現在も現役で活躍している。
直近の注目記事
もう失敗しない!製造業向け機械学習Tips(4):
偽相関の罠に陥らない、製造業における機械学習を用いた要因分析のコツ(MONOist)
もう失敗しない!製造業向け機械学習Tips(3):教師データが足りないと「異常予測」は難しい、ならば「異常検知」から始めよう (1/2)(MONOist)
もう失敗しない!製造業向け機械学習Tips(2):機械学習による逆問題への対処法、材料配合や工程条件を最適化せよ(MONOist)
もう失敗しない!製造業向け機械学習Tips(1):機械学習で入ってはいけないデータが混入する「リーケージ」とその対策 (1/2)(MONOist)
-
Apache AirflowとDataRobotを連携してMLOpsワークフローを強化する方法
2024/05/15· 推定読書時間 2 分 -
DataRobot 最新バージョンで実現する生成AIほか最新機能とそれを支える新たなアーキテクチャ
2024/05/13· 推定読書時間 3 分 -
生成AIの取り組みが失敗する6つの理由とその解決策
2024/04/30· 推定読書時間 4 分
最近のブログ記事